루빅스는 실시간으로 사용자 반응을 분석하여 콘텐츠를 추천하는 카카오의 추천 시스템입니다. 2015년 5월에 다음 포털 뉴스 서비스의 일부 사용자를 대상으로 뉴스 기사를 추천하기 시작했고, 한달 뒤인 6월부터 전체 사용자에게 확대 적용했습니다. 현재는 다음 뉴스 뿐 아니라 카카오톡 채널 등 다양한 콘텐츠 서비스에서 루빅스의 추천 서비스를 사용하고 있습니다. 다음 뉴스에 루빅스를 적용한 후에 나타난 긍정적인 효과와 지표 상승에 관한 이야기는 이전에 몇 차례 다룬 적이 있습니다.(관련 글 참고)
이번 글에서는 루빅스가 실시간 추천 시스템으로서 어떤 특징을 가지고 있고 어떻게 구현하였는가를 이야기해 보려고 합니다.
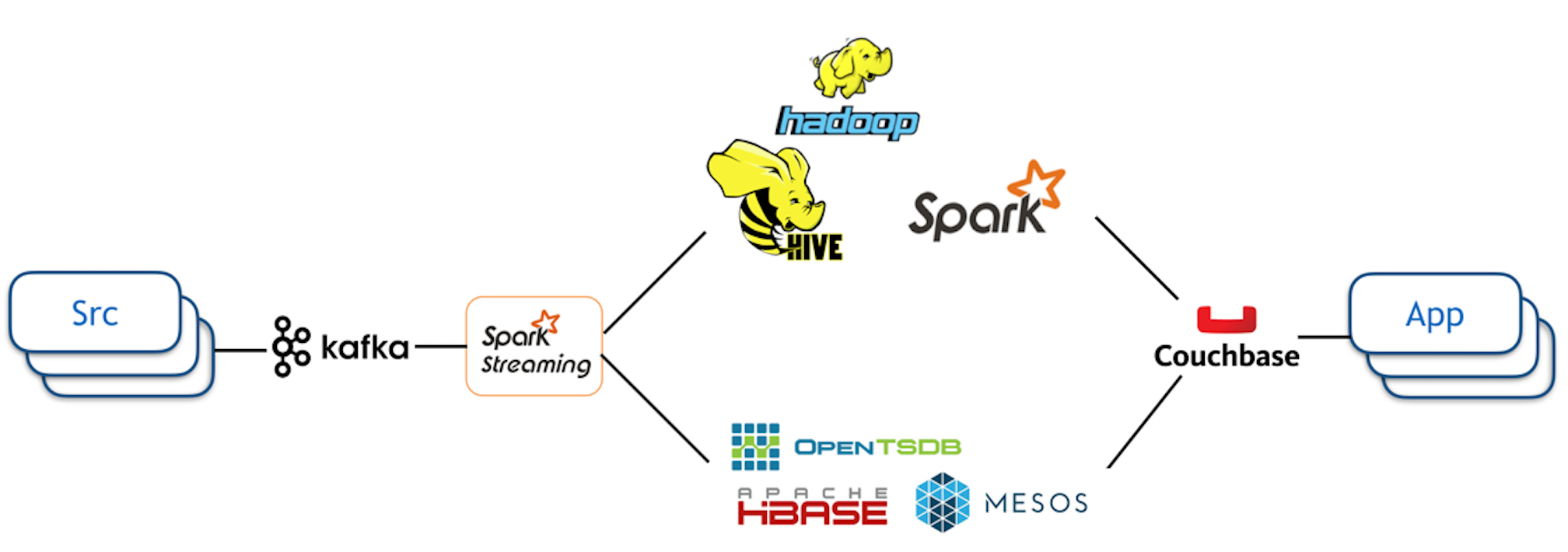
실시간 데이터 처리
루빅스의 첫 적용 사례는 다음 뉴스 서비스 였습니다. 그런 이유로 개발 초기부터 뉴스 서비스에 특화된 요구사항이 많이 반영 되었습니다. 뉴스 콘텐츠는 영화나 음악, 도서와 조금 다른 점이 있는데요, 다른 콘텐츠에 비해서 생명주기가 상당히 짧습니다. 이런 차이점을 고려하면, 뉴스 기사 추천은 사용자의 반응을 최대한 빠르게 수집 및 처리하여 추천 랭킹에 반영해야 합니다. 사용자의 피드백을 반영하기까지 너무 오래 걸린다면, 새롭게 추천된 기사가 뉴스로서 더이상 가치 없을 수도 있기 때문입니다.
저희는 사용자로부터 전달되는 피드백을 최대한 신속하고 안전하게 처리할 수 있는 시스템을 만들어야 했습니다. 사용자 피드백 메시지가 대량으로 들어오는 환경에서도 안정적으로 동작하는 메시지 큐와 메시지 큐에 저장된 데이터를 빠른 속도로 처리할 수 있는 데이터 스트림 처리기를 이용하기로 했습니다.
1. 메시지 큐
Apache Kafka 는 대량의 메시지를 안전하게 저장할 수 있는 분산 메시징 시스템입니다. 빠르고, 확장성이 있으며, 데이터 손실을 방지할 수 있도록 복제 기능을 제공합니다. 이미 검증된 적용 사례가 많이 있었으므로, 루빅스에도 Apache Kafka 를 메시지 큐 시스템으로 채택했습니다.
2. 데이터 스트림 처리기
메시지 큐에 저장된 데이터를 빠르게 읽어서 처리한 결과는 추천 랭킹을 위한 기계 학습에 사용됩니다. 실시간으로 데이터 스트림을 처리할 수 있는 여러 기술 중에서 루빅스는 Apache Spark Streaming 을 사용하고 있습니다. 이렇게 결정하게 된 이유로는 첫째, 개발할 당시에 Apache Spark 이 상당한 인기를 모으고 있었고, 둘째로는 무엇보다도 루빅스 개발팀 내에 스칼라 언어에 익숙한 개발자가 많이 있었기 때문입니다. Apache Spark 은 애플리케이션 개발을 위한 주요 언어로 스칼라를 잘 지원하며, 루빅스 개발자들은 익숙한 언어로 개발을 시작할 수 있었으므로 학습의 부담을 많이 줄일 수 있었습니다.
3. 실시간 처리와 배치 처리로 분리
데이터의 용도와 성격에 따라서 일부는 굳이 실시간으로 처리할 필요가 없습니다. 이런 종류의 데이터는 일정 기간동안 모아서 주기적으로 배치 처리를 합니다. 루빅스는 배치 처리를 위해서 Spark 과 Hive 을 사용하고 있는데, 이렇게 실시간과 배치로 처리된 데이터를 결합하여 최종 추천 서비스에서 사용하고 있습니다.
루빅스에서는 사용자의 피드백이 수 초 이내에 새로운 추천 결과에 반영됩니다.
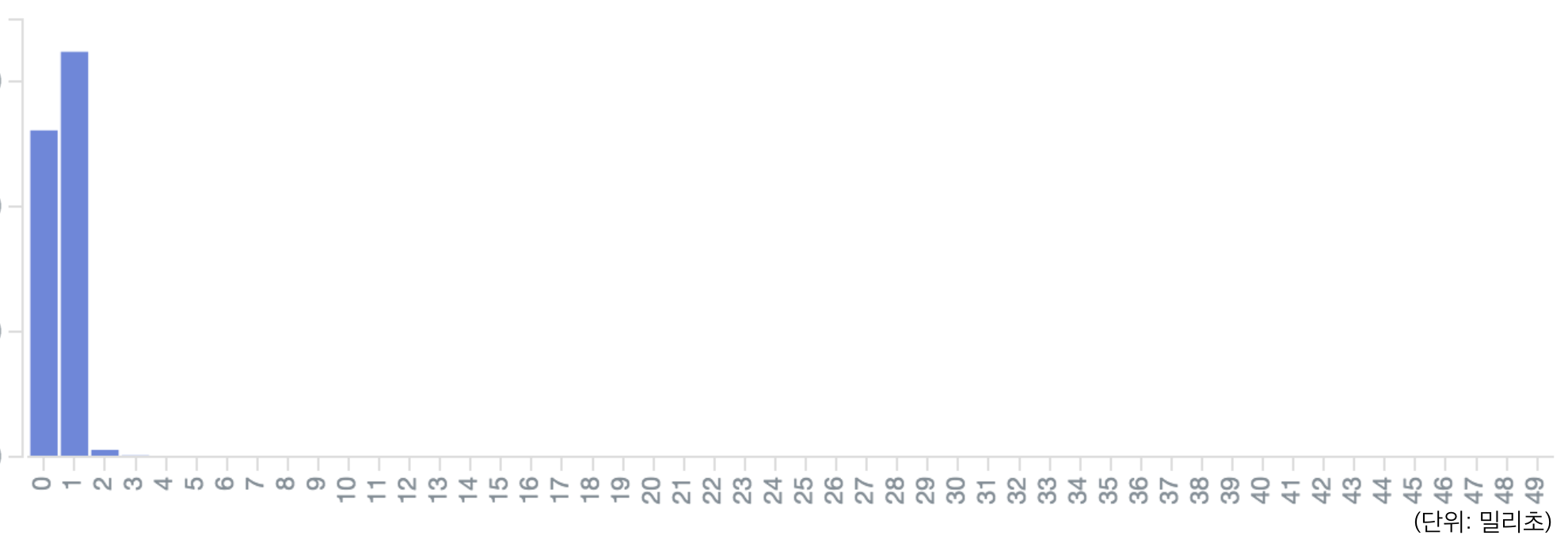
빠른 응답 속도
루빅스에서 추천 결과를 반환하는 응답 속도는 콘텐츠 서비스 자체의 응답 속도에 직접 영향을 줍니다. 따라서 루빅스의 응답 속도는 빠르면 빠를수록 좋습니다.
저희는 응답 속도를 빠르게 만들기 위해서 몇 가지 요소를 고려하여 시스템을 설계 했습니다.
- 디스크 혹은 네트쿼크 IO 발생을 최소화
- 효율적인 알고리즘
- 병렬로 실행되는 코드
이 중에서 3번 항목에 대해서 좀 더 이야기해 보겠습니다. 병렬로 실행되는 프로그램은 여러 개의 논리적인 쓰레드로 구성됩니다. 멀티 쓰레드 프로그래밍에서 가장 골치 아픈 문제는 공유 자원을 관리하는 것입니다. 여러 개의 쓰레드가 공유 자원을 한꺼번에 변경하다 보면 race condition 이 발생하기도 합니다. 대개는 이런 문제를 해결하기 위해서 공유 자원에 접근하기 전에 락(Lock)을 걸고, 접근이 끝나면 락을 풀어 버립니다. 그러나 락을 사용하는 것도 생각만큼 간단하지 않습니다. 한 쓰레드가 공유 자원에 접근하는 동안에 다른 쓰레드는 차례를 기다려야 하기 때문에 프로그램 실행 속도가 느려지곤 합니다. 또 락을 사용하는 순서가 꼬여 버리면 deadlock 문제가 발생하기도 합니다.
요즘은 동시성 프로그래밍을 하기 쉽다는 장점 때문에 함수형 언어들이 많은 인기를 얻고 있습니다. 멀티 쓰레드 프로그래밍에서 공유 자원 관리가 어려운 이유는 공유 자원의 상태가 변하기(mutable) 때문입니다. 변하지 않는(immutable) 데이터는 락을 사용하지 않더라도 여러 개의 쓰레드에서 안전하게 접근할 수 있습니다. 함수형 언어에서 모든 데이터는 불변이므로 위에서 이야기한 멀티 쓰레드 프로그래밍의 어려움을 해결할 수 있습니다.
저희는 이런 함수형 언어의 장점을 활용할 수 있는 스칼라를 사용하고 있습니다. 스칼라는 순수 함수형 언어는 아니지만, 여전히 함수형 언어로서의 특징을 가지고 있습니다. 앞에서도 이야기한 것처럼 루빅스 개발팀 내에는 이미 스칼라 언어에 익숙한 개발자가 많이 있었으므로, 스칼라를 주요 개발 언어로 채택할 수 있었습니다. 스칼라에서 지원하는 Future 와 Actor 를 이용하여 비동기/비차단 방식으로 병렬 실행되는 코드를 작성하기 한결 쉬워졌으며, 이 덕분에 루빅스의 응답 속도는 꽤 빠른 편입니다.
현재 루빅스는 99% 요청을 3ms 이내에 처리하며, 99.9999% 요청을 150ms 이내에 처리하고 있습니다.
확장성
카카오의 다양한 콘텐츠 서비스에서 루빅스의 추천 서비스를 사용하게 되면서, 루빅스에서 처리하는 요청량도 급격히 증가했습니다. 저희는 프로젝트 초기부터 확장성을 염두에 두고 시스템을 설계 했으므로, 트래픽의 급격한 증가에 대응할 수 있었습니다.
상태를 저장하는 구조는 확장하기 어렵습니다. 이전의 상태가 저장된 특정 인스턴스로 요청이 계속 전달된다면 단순히 인스턴스 수를 늘려도 트래픽이 골고루 분산되지 않기 때문입니다. 서비스에 영향을 주지 않으면서 수평으로 확장이 가능한 구조를 만들기 위해서 각 인스턴스는 상태가 없는 구조로 설계 되었습니다.
분산 NoSQL 데이터베이스인 Couchbase 를 사용한 것도 확장성 있는 구조 설계를 가능하게 했습니다. Couchbase 에서는 노드를 추가하거나 제거하고 데이터를 재분배하는 기능이 쉽게 지원됩니다. 이런 특징 덕분에 트래픽의 증감에 따라서 노드 수를 쉽게 조절할 수 있었습니다.
2016년 4월 기준으로 루빅스로 유입되는 요청량이 시스템 오픈 이후 60배 이상 늘었으며, 피크타임에 20만 QPS 요청을 처리하고 있습니다.
장애 내구성
서비스를 운영하다 보면 크고 작은 장애가 항상 발생합니다. 장애의 원인은 아주 다양합니다. 코드에 버그가 있거나, 급증하는 트래픽을 감당하지 못 해서 인스턴스가 죽기도 합니다. 때로는 네트워크 스위치나 서버의 메인보드가 고장 나는 경우도 있습니다.
중요한 것은 예측하기 어려운 다양한 이유로 부분적인 장애는 발생할 수 있지만, 그것이 서비스 전체에 영향을 주는 장애로 이어져서는 안 된다는 점입니다. 루빅스는 서비스 장애를 최소화할 수 있는 구조를 만들기 위해서 많은 고민을 했습니다.
- 루빅스는 상태가 없는 구조로 설계되어 있습니다. 따라서 특정 인스턴스에 문제가 발생하면 전체 서비스에 영향을 주지 않으면서 다른 인스턴스에서 이어서 요청을 처리할 수 있습니다.
- Couchbase 는 데이터를 여러 노드에 복제하여 분산 저장하는 기능을 제공합니다. 데이터가 저장된 노드에 문제가 발생하더라도, 복제 데이터를 가진 다른 노드에서 요청을 처리할 수 있으므로 전체 서비스에는 영향이 없습니다.
- Apache Mesos 와 Marathon, Apache Aurora 프레임워크를 사용하여, 애플리케이션이 비정상적으로 종료 하더라도 자동으로 다시 실행될 수 있도록 했습니다.
- 마이크로 서비스 아키텍처를 구성하고 있는 일부의 구성요소에서 장애가 발생하더라도 인접한 다른 구성요소로 장애가 전파되지 않도록 차단합니다. 의존성이 있는 타 구성요소의 장애 때문에 응답을 받을 수 없거나 비정상적인 결과를 받는 경우에는 미리 준비된 fallback 정책에 따라서 기본값을 사용하며, 장애로는 이어지지 않습니다.
- 시스템 통합 테스트를 상시 실행하고 있으며, 비정상적인 상황이 발견되면 카카오톡으로 개발팀 전체에 즉시 알림 메시지를 전송합니다. 데이터 무결성 검사를 포함하여 사람이 인지하기 어려운 다양한 에러 상황을 빠르게 감지하고 대응할 수 있습니다.
2016년 4월 현재 루빅스는 서비스 오픈 이후로 99.998% 가용성을 보이고 있으며, 작년 9월 이후로 루빅스의 장애시간은 0을 기록하고 있습니다.
맺음말
지금까지 루빅스의 주요 특징과 사용 중인 기술을 설명 드렸는데요, 이 글이 저희와 비슷한 문제를 해결하려고 고민하고 있는 사람들에게 도움이 되었으면 합니다.
관련 글
- 내 입맛에 딱 맞는 뉴스를 보여주는 루빅스!, Kakao 블로그
- 맞춤형 추천뉴스 루빅스를 소개합니다, Kakao 블로그
- 루빅스는 완성 없는 시스템, 계속 진화할 것, 마이크로소프트웨어 (스크랩)
- 카카오 “맞춤형 추천 ‘루빅스’ 적용 후 뉴스 다양성 늘었다”, 한국경제
- “개인 맞춤형” 다음 뉴스..네이버 대항마 가능할까, 연합뉴스
- 머신러닝 기반 뉴스 서비스도 해볼만한 승부, 지디넷코리아
이 글은 카카오에서 루빅스TF를 이끌고 있는 sawyer.seo가 쓴 글입니다. 루빅스 덕분에 뉴스에도 등장하고, 국정감사 보고서도 만들고… 버라이어티한(?) 나날을 보내고 있는…(자세한 설명은 생략한다)
기술 블로그를 통해서 카카오가 자체 개발한 다양한 기술들을 소개합니다. 현재로썬 카카오 내부에서만 사용할 수 있다는 점이 아쉽지만, 함께 나눌 수 있는 부분들은 지속적으로 발굴하고 공개할 계획이니, 관심을 갖고 지켜봐주세요.
물론, 카카오 크루가 되시면 지금이라도 사용하실 수 있고 또 개발에 참여하실 수 있습니다 ^^;
- 커버 이미지 출처: Cube © Michael Chen