지금까지 SSD 드라이브의 내부적인 작동 방식에 대해서 살펴 보았다. 또한 SSD를 접근할 때 어떤 방식이 사용되어야 하며, 그리고 그 접근 방법이 다른 방법보다 왜 나은지 등의 이해를 돕는 자료들도 제공했다. 이번 챕터에서는 읽기와 쓰기는 어떻게 처리되어야 하는지, 그리고 읽고 쓰기가 동시에 발생할 때 서로 어떤 간섭 효과를 내게 되는지를 살펴보도록 하겠다. 그리고 성능 향상을 위해서 파일 시스템 레벨에서 가능한 최적화에 대해서도 조금 언급하도록 하겠다
7. 액세스 패턴
7.1. 시퀀셜과 랜덤 I/O의 정의
이번 섹션에서 사용되는 시퀀셜(“sequential”)과 랜덤(“random”)이라는 단어로 SSD 액세스를 의미한다. 이전 I/O 오퍼레이션의 마지막 논리 블록 주소(LBA) 직후의 논리 블록 주소(LBA)를 시작 지점으로 SSD를 접근하는 경우 시퀀셜이며, 그렇지 않은 경우를 랜덤이라고 한다. 그리고 FTL에 의해서 동적으로 블록 맵핑이 실행되기 때문에, 논리 주소가 연속적이라고 해서 실제 물리적인 데이터의 위치가 연속적인 것은 아닐 수도 있다는 것도 기억해두자.
7.2. 쓰기
벤치마킹과 제조사의 데이터 시트를 보면, 랜덤 쓰기는 시퀀셜 쓰기보다 느리다는 것을 알 수 있다. 물론 이건 정확하게 랜덤 쓰기의 워크로드가 어떠냐에 따라서 틀린 이야기일 수도 있다. 하지만 쓰기 데이터가 작다면(여기에서 작은 데이터의 기준은 Clustered block의 크기보다 작은 것을 의미하며, 예를 들어서 32MB 미만 정도로 생각할 수 있다), 데이터 시트나 벤치마킹의 결과에서와 같이 랜덤 쓰기는 시퀀셜 쓰기보다 느리다. 그러나 Clustered block의 크기 또는 그 배수의 데이터를 랜덤으로 쓰기한다면, 시퀀셜 쓰기와 거의 비슷한 수준의 성능을 내게 된다. 섹션 6에서 본 것과 같이 SSD의 내부 병렬 처리는 최소 하나의 Clustered block이 처리될 때 최대 처리 능력을 보여주기 때문이다. 그래서 이렇게 대량의 데이터를 기록하는 경우에는 시퀀셜이든지 랜덤이든지, 내부적으로 여러 채널과 여러 칩을 사용하는 내부 병렬 처리 방식은 동일하게 사용된다(데이터가 여러 채널과 여러 칩으로 스트라이핑되는 것이다). 또한 이 경우 SSD가 지원하는 내부적인 병렬 처리 능력들을 모두 활용하게 되는 것이다. Clustered block의 쓰기 오퍼레이션은 섹션 7.3에서 다시 살펴보도록 하겠다. 지금은 성능적인 측면에서 (그림 8과 9) 쓰기 버퍼의 크기가 Clustered block(일반적인 SSD에서는 16MB 또는 32MB)에 가까워지거나 더 커지면서 랜덤 쓰기의 스루풋이 시퀀셜 쓰기와 비슷해지는 것을 확인할 수 있다.
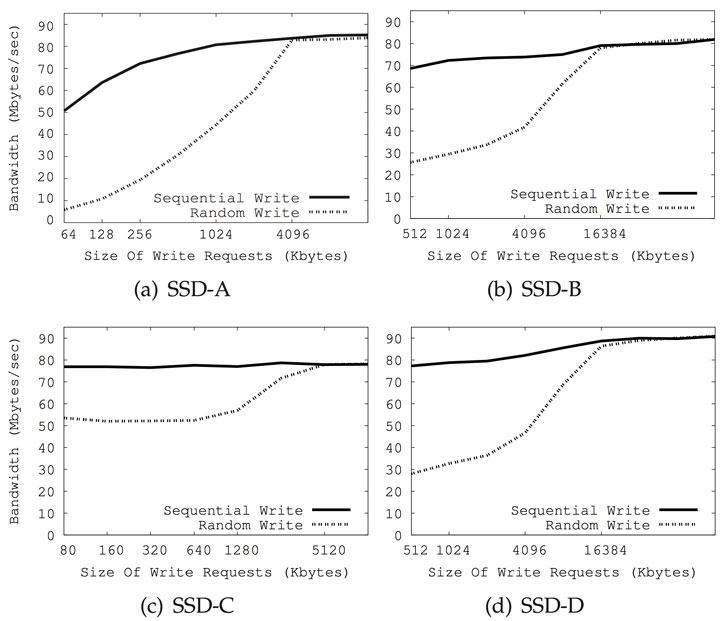 (출처: 2012년 김 재홍 외 1)
(출처: 2012년 김 재홍 외 1)
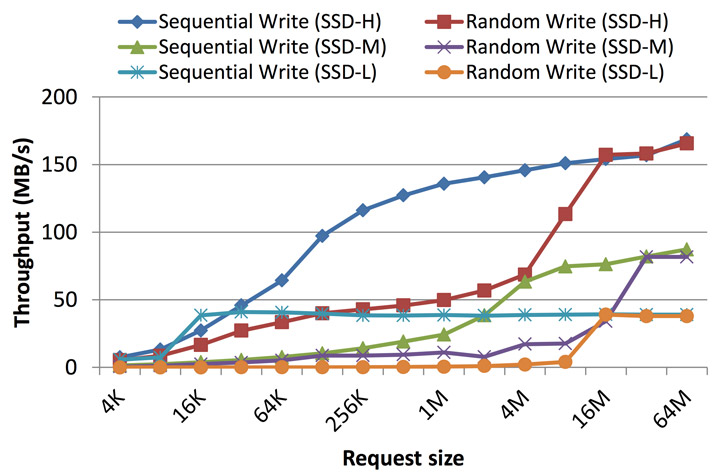 (출처: 2012년 민 창우 외 2)
(출처: 2012년 민 창우 외 2)
하지만 쓰기가 작다면(여기에서 작다는 것은 NAND 플래시 페이지의 크기보다 작은 16KB 미만을 의미), 컨트롤러는 블록 맵핑을 위한 메타 데이터 관리를 위해서 더 많은 일을 해야 한다. 일부 SSD 드라이브는 논리 블록 주소와 물리 블록 주소의 맵핑을 위해서 트리 형태의 데이터 구조체를 사용한다3. 그리고 작고 빈번한 랜덤 쓰기는 SSD 드라이브의 메모리(RAM)의 맵핑 테이블을 매우 빈번하게 업데이트해야 함을 의미한다. 그리고 메모리의 맵핑 테이블은 플래시 메모리로 동기화되어야 하는데3 4, 메모리의 모든 업데이트는 플래시 메모리의 많은 쓰기를 발생시킨다. 하지만 시퀀셜 쓰기는 메타 데이터의 변경을 덜 필요로 하기 때문에 플래시 메모리에 동기화하는 회수도 줄어들게 된다.
랜덤 쓰기가 항상 시퀀셜보다 느린 것은 아니다
만약 쓰기가 Clustered block의 크기보다 작다면, 랜덤 쓰기는 시퀀셜 쓰기보다 느릴 것이다. 하지만 쓰기가 Clustered block과 동일하거나 배수 크기의 데이터를 기록한다면, 랜덤 쓰기도 SSD의 모든 병렬 처리 능력을 활용하게 되며 그로 인해서 시퀀셜 쓰기와 비슷한 스루풋을 낼 수 있게 된다.
랜덤 쓰기의 데이터 크기가 작으면 시퀀셜보다 스루풋이 떨어지는 또 다른 이유로는 블록의 “copy-erase-write” 오퍼레이션이 많이 발생하기 때문이다. 반면 최소 블록 크기의 데이터를 저장하는 시퀀셜 쓰기는 빠른 “switch-merge” 최적화가 사용될 수 있다. 게다가 작은 랜덤 쓰기는 데이터를 랜덤하게 무효화하기 때문에, 최악의 경우 많은 블록들이 단 하나의 무효화된 페이지를 가지게 된다. 이는 “stale” 페이지들이 일부 영역에 집중화(localizing)되는 것이 아니라, 전체 물리 공간에 골고루 퍼뜨리는 효과를 내게 되는데 이를 “내부 프레그멘테이션(internal fragmentation)”이라고 한다. 내부 프레그멘테이션은 Garbage-collection이 “free” 페이지를 만들어내기 위해서 많은 블록 삭제(Erase)를 실행하게 만드는 “Cleaning efficiency”를 유발하게 된다.
마지막으로 동시성 측면에서 보면, 하나의 쓰레드에서 대량의 버퍼를 기록하는 것은 많은 쓰레드가 동시에 작은 데이터를 쓰기하는 것만큼 빠르다. 단일 쓰레드로 대량 데이터 쓰기시에는 SSD의 내부 병렬 처리 능력을 모두 활용할 수 있기 때문이다. 그래서 여러 쓰레드로 동시에 병렬로 데이터 쓰기를 실행하는 것은 SSD 드라이브의 스루풋을 향상시키지 못한다3 4. 역으로 많은 동시 쓰레드가 데이터를 쓰기하는 것은 단일 쓰레드 쓰기보다 레이턴시를 증가시키는 역 효과만 낳게 될 것이다5 6 7.
하나의 큰 데이터 쓰기는 많은 동시 쓰기보다 낫다
하나의 큰 쓰기 요청은 병렬로 실행되는 많은 작은 쓰기 요청만큼의 스루풋을 낼 수 있다. 하지만 레이턴시 측면에서 보면, 하나의 큰 쓰기 요청은 많은 쓰기 요청보다 더 나은 응답 속도를 보장받을 수 있다. 그래서 가능하다면 큰 데이터를 한번에 기록하는 것이 좋다.
버퍼링되지 못하는 작은 쓰기는 멀티 쓰레드로 기록하는 것이 도움이 된다
많은 동시 쓰레드로 작은 쓰기 요청은 하나의 작은 쓰기 요청보다 나은 스루풋을 제공한다. 만약 I/O 데이터가 작고 버퍼링 또는 배치로 묶을 수 없다면 멀티 쓰레드로 쓰기를 수행하는 것이 좋다.
7.3. 읽기
읽기는 쓰기보다 빠른다. 시퀀셜 읽기와 랜덤 읽기의 성능은 워크로드에 의존적이다. FTL은 논리 블록과 물리 블록을 동적으로 맵핑하며, 쓰기를 여러 채널로 스트라이핑해준다. 이 방법을 때로는 “Write-order-based” 맵핑이라고도 한다5. 만약 처음 데이터가 기록되던 순서와는 무관하게 완전히 랜덤하게 데이터 읽기 요청이 발생한다면, 설령 읽기 요청이 연속적이라 하더라도 여러 채널로 분산되어 처리된다는 것을 보장할 수 없다. 연속적인 랜덤 읽기가 하나의 채널에 연결된 다른 블록들을 액세스할 수도 있으며, 이런 경우에는 SSD의 내부적인 병렬 처리 능력을 활용하지 못하게 되는 것이다. Acunu는 그의 블로그8에서, 읽기 성능은 데이터의 읽기 패턴이 얼마나 쓰기 패턴과 일치하느냐에 직접적으로 연결된다고 언급하고 있다.
읽기 성능 향상을 위해서, 연관된 데이터를 같이 쓰도록 하자
읽기 성능은 쓰기 패턴의 결과이다. 대량의 데이터가 한번에 기록된다면, 그 데이터는 NAND 플래시 칩에 골고루 분산되어서 저장될 것이다. 그래서 연관된 데이터들은 최대한 동일 페이지와 블록 그리고 클러스터링 블록에 기록되도록 하는 것이 좋다. 그래야지만 SSD의 병렬 처리 능력을 이용해서 나중에 한번의 I/O로 빠르게 읽을 수 있다.
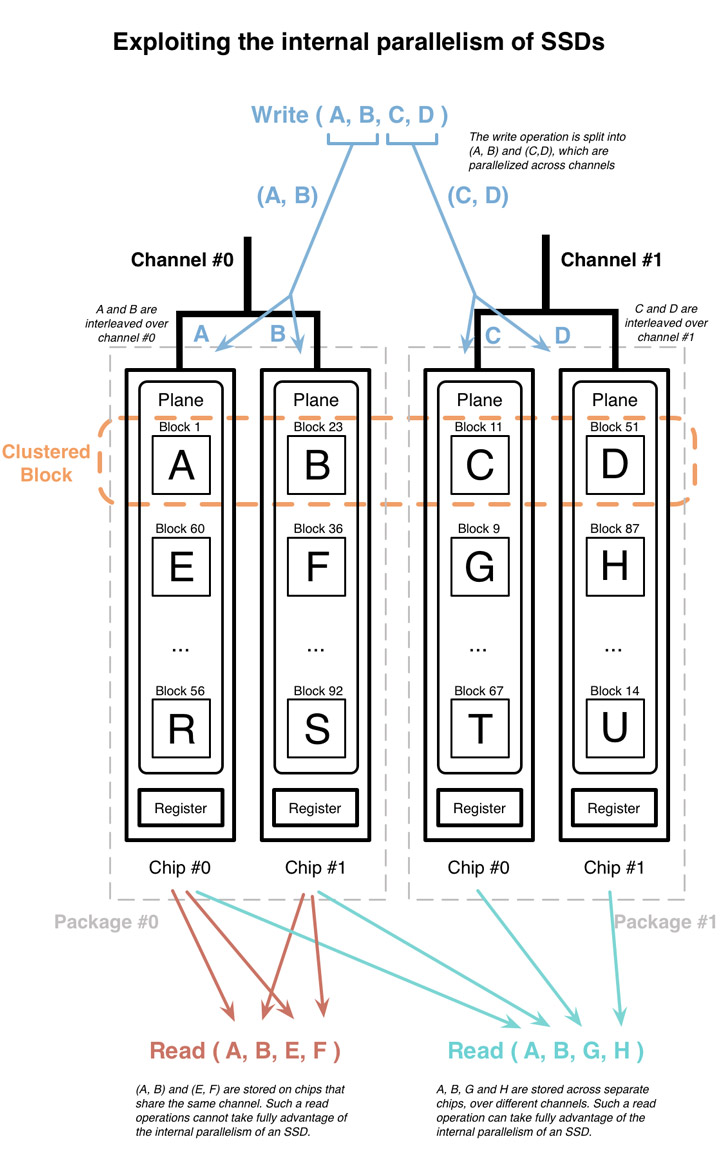
아래의 그림 10은 하나의 플레인을 가진 칩이 4개 그리고 2개의 채널을 가진 SSD를 보여주고 있다.
참고로 대 부분의 SSD는 항상 하나의 칩당 2개 또는 그 이상의 플레인을 가지고 있는데,
여기에서는 설명의 단순화를 위해서 칩당 하나의 플레인만 있는 그림을 그렸다. 대문자는 NAND 플래시 블록 크기의 데이터를 의미한다.
그림 10의 최 상단에 표시된 오퍼레이션은 [A B C D] 데이터를 시퀀셜하게 쓰는 것을 의미하는데, 여기에서는 Clustered block의 사이즈이다.
쓰기 오퍼레이션은 빠른 처리를 위해서 병렬 처리와 인터리빙 모드를 이용해서 4개의 플레인으로 스트라이핑된다.
4개의 블록은 논리 블록 주소상으로는 연속되게 시퀀셜하지만, 실제 내부적으로는 각각의 플레인에 저장된다.
“Write-order-based” FTL에서는, 플레인의 모든 블록은 동등하게 유입된 쓰기를 처리하게 된다.
그래서 Clustered block은 플레인의 동일한 PBN을 가질 필요가 없다.
예를 들어서 그림 10에서는, 첫 Clustered block은 4개의 서로 다른 플레인에 속한 블록에 저장되며, 각 플레인에서의 PBN은 1, 23, 11 그리고 51을 갖게 된다.
그림 10의 하단에는 2번의 읽기 오퍼레이션을 보여주고 있는데, [A B E F]와 [A B G H] 데이터를 읽고 있다. [A B E F] 읽기를 위해서,
A와 E는 동일 플레인에 속해 있으며, B와 F는 다른 플레인에 속해 있다.
그래서 [A B E F]는 하나의 채널을 통해서 2개의 플레인으로부터 읽게 된다.
[A B G H] 읽기에서, A와 B 그리고 G와 H는 모두 각각 다른 플레인에 저장되어 있기 때문에 [A B G H]는 2개의 채널을 이용해서 4개의 플레인으로부터 동시에 읽을 수 있다.
데이터를 읽을 때, 더 많은 채널과 플레인을 이용할 수 있다는 것은 좀 더 내부 동시성 처리 기능을 활용할 수 있음을 의미하며 더 나은 읽기 성능을 보장받을 수 있게 된다.
내부적인 병렬 처리로 인해서, 성능 향상을 위해서 멀티 쓰레드를 이용하여 동시에 데이터를 읽지 않아도 된다. 쓰레드는 읽고자 하는 데이터의 내부적인 맵핑 정보를 알지 못하기 때문에 내부적인 병렬 처리의 효과를 활용할 수가 없고 결국 동일 채널의 데이터를 이용하게 될 가능성도 있다. 또한 멀티 쓰레드로 동시에 데이터를 읽게 되면, SSD의 Read ahead (Prefetching buffer) 효과를 저해할 수도 있다는 게시물도 있다5.
단일 쓰레드의 대량 데이터 읽기는 멀티 쓰레드의 작은 읽기보다 낫다
동시 랜덤 읽기는 SSD의 Read ahead 메커니즘을 제대로 활용하지 못할 수도 있다. 또한 다중으로 논리 블록 주소를 액세스하는 것은 내부적인 병렬 처리 기능을 활용하지 못하고 결국 동일 칩으로 집중되어 버릴 수도 있다. 게다가 대량 데이터 읽기 오퍼레이션은 연속된 주소를 액세스함으로써 Read ahead 버퍼(Read ahead 버퍼가 있다면)를 활용할 수 있다. 결과적으로 한번에 대량의 데이터를 읽는 방법이 추천된다.
SSD 제조사는 일반적으로 페이지나 블록 그리고 Clustered block의 크기에 대해서는 공개하지 않는다. 그러나 단순한 테스트1 5를 통해서 SSD의 기본적인 특성을 상당한 확률로 알아낼 수 있다. 이러한 정보는 데이터를 읽고 쓸 때 버퍼의 크기를 최적화하는데 활용할 수 있으며, 해당 SSD의 특성에 맞게 포맷시에 파티션을 얼라인(Align)할 수도 있다. 이런 내용은 섹션 8.4를 참조하도록 하자.
7.4. 동시 읽고 쓰기
작은 데이터를 읽고 쓰기는 작업이 동시에 발생하게 되면 성능 저하를 유발할 수 있다3 5. 동일 내부 자원을 위해서 읽고 쓰기가 경합을 할 수 있기 때문이다. 또한 읽기와 쓰기를 혼합하면 Read ahead와 같은 내부 최적화 메커니즘을 활용하지 못하게 만들기도 한다.
읽기와 쓰기 요청의 분리
작은 읽기와 쓰기가 혼합되어 동시에 실행되는 워크로드는 내부적인 캐싱이나 Read ahead 메커니즘이 제대로 활용되지 못하게 만들어서 전체적인 스루풋을 떨어뜨리게 된다. 동시에 읽고 쓰기 요청을 실행하는 것은 피하고 하나씩 큰 용량의 청크(Clsutered block 크기)를 읽고 쓰도록 하는 것이 좋다. 예를 들어서 1000개의 파일이 업데이트 되어야 한다면, 파일을 한 개씩 루프로 읽고 쓰는 형태로 처리할 수도 있다. 하지만 이런 방법은 느리게 처리될 것이다. 가능하다면 한번에 1000개의 파일을 한번에 읽고 그 다음에 1000개의 파일을 한번에 업데이트하도록 하는 것이 좋다.
8. 시스템 최적화
8.1. 파티션 얼라인먼트 (Partition alignment)
섹션 3.1에서 설명된 바와 같이, 쓰기는 페이지의 크기에 맞춰서 실행된다. 페이지의 크기에 맞춰서 쓰기 요청된 데이터는 NAND 플래시의 물리 페이지에 바로(Read-modify-write 과정 없이) 기록될 수 있다. 기록하는 데이터가 SSD 페이지 크기라 하더라도, 물리 페이지와 맞춰지지(Alignment) 않은 쓰기는 2개의 NAND 플래시 물리 페이지에 기록되어야 한다. 이런 현상이 생기면, SSD 드라이브는 두번의 “Read-modify-write” 오퍼레이션을 수행해야 한다9. 그래서 SSD 드라이브의 쓰기에서 사용되는 파티션이 NAND 플래시 페이지 사이즈와 물리적으로 맞춰졌는지(Align)는 매우 중요한 요소이다. 여러 가이드 문서와 튜토리얼에서 SSD 드라이브를 포맷할 때 어떻게 파티션 파라미터를 설정하는지 소개되고 있다10 11. 구글에서 검색해보면 특정 SSD 드라이브 모델의 페이지와 블록 사이즈 그리고 Clustered block의 크기를 확인할 수 있다. 만약 이런 정보들이 구글 검색으로 확인이 안될 경우에는, 리버스 엔지니어링을 통해서 이런 파라미터 값들을 확인할 수 있다1 5. 파티션 얼라인먼트를 통해서 성능을 상당히 끌어올릴 수 있다는12 것은 이미 여러 문서12에서 확인되었다. 또한 크진 않지만, 파일 시스템을 건너뛰어서 SSD 드라이브에 직접 쓰기를 실행하는 경우에도 성능 향상을 기대할 수 있다13.
Align the partitio
SSD 플래시 메모리와 논리적인 쓰기가 정확하게 맞춰지도록 하기 위해서, 반드시 파티션이 NAND 플래시 메모리의 페이지와 맞춰지도록(Align) 포맷해야 한다.
8.2. 파일 시스템 파라미터
섹션 5.1에서 소개되었듯이, 모든 파일 시스템이 TRIM 명령14을 지원하는 것은 아니다.
리눅스 2.6.33 또는 그 이상의 버전에서 ext4와 XFS 파일 시스템만 TRIM 명령을 지원하는데,
이때에도 discard 마운트 옵션이 활성화되어야 한다. 또한 파티션을 마운트할 때, noatimer,nodiratime
그리고 relatime 마운트 옵션을 활성화하여 파일의 메타 정보 업데이트를 하지 않도록 해서 성능 향상을 기대할 수도 있다
(물론 메타 정보 업데이트가 불필요한 경우에만) 15 11 16 17.
TRIM 명령 활성화
파일 시스템과 리눅스 커널이 TRIM 명령을 지원하는지 확인하도록 하자. TRIM 명령은 호스트에서 블록이 삭제되는 경우에, 그 삭제 블록 정보를 SSD 드라이브로 전달해주는 역할을 하며, 이렇게 삭제 블록 정보를 SSD 컨트롤러가 알게 되면 Garbage-collection에서는 삭제된 블록에 대해서 불필요한 복사 작업을 피할 수 있게 된다.
8.3. 운영 체제의 I/O 스케줄러
리눅스의 기본 I/O 스케줄러는 CFQ(Completely Fair Queuing)이다.
CFQ는 요청된 I/O를 모아서 배치로 기록하기 때문에 스피닝 HDD(Spinning hard disk)의 seek-time을 최소화 해준다.
SSD 드라이브는 기계적인 장치가 아니기 때문에, 이런 형태의 I/O 요청의 재 정렬(Re-ordering)은 필요치 않다.
많은 가이드 문서와 토론 사이트에서는 I/O 스케줄러를 CFG에서 NOOP이나 Deadline으로 변경하는 것이 SSD의 레이턴시를 줄여줄 것이라고 말하고 있다.16 18.
하지만 리눅스 버전 3.1부터, CFQ는 SSD 드라이브를 위한 어느 정도의 최적화 알고리즘을 가지고 있다19.
SSD로 주어지는 워크로드에 따라서 I/O 스케줄러별 성능 차이를 보여주는 벤치마크 자료들도 있다15 20 21 22.
개인적인 생각으로는 워크로드가 아주 특별하지 않고 실제 응용 프로그램 벤치마킹 테스트에서 다른 I/O 스케줄러가 더 나은 성능을 보여주는 것이 아니라면,
굳이 CFQ 스케줄러에서 NOOP이나 Deadline으로 바꿀 필요는 없어 보인다.
8.4. 스왑 (Swap)
Swap이 자주 사용되는 경우에는 많은 I/O 요청이 발생하기 때문에,
SSD 드라이브에 스왑 파티션이 있는 경우 SSD의 랜덤 쓰기가 자주 발생하며 그로 인해서 수명이 훨씬 더 빨리 줄어들 수 있다.
리눅스 커널에서는 vm.swappiness 커널 파라미터를 기준으로 얼마나 자주 페이지들을 디스크로 스왑할지를 결정한다.
vm.swappiness 값으 0부터 100까지 설정할 수 있는데,
0은 커널이 최대한 스왑을 하지 않도록 하며 100은 최대한 커널이 디스크의 스왑 영역을 사용하도록 유도한다.
예를 들어 Ubuntu에서는 vm.swappiness 기본 값이 60이다. SSD 드라이브를 사용하는 경우에는 vm.swappiness 값을
최대한 낮은 값으로 설정하여 SSD로 기록되는 데이터를 최소화하여 SSD 드라이브의 수명을 늘리는 것이 좋다16 23.
어떤 가이드에서는 vm.swappiness 값으로 1을 추천하는데, 실질적으로 1은 0과 동일한 효과를 낸다17 18.
8.5. 임시 파일
굳이 디스크에 기록되지 않아도 되는 모든 임시 파일들과 로그 파일들은 SSD 드라이브의 P/E cycle을 낭비하는 것이다.
그러한 파일들은 가능하다면 RAM을 이용한 tmpfs 파일 시스템으로 유도하도록 하자16 17 18.
This articles are translated to Korean with original author’s(Emmanuel Goossaert) permission. Really appreciate his effort and sharing.
Original articles :
- Part 1: Introduction and Table of Contents
- Part 2: Architecture of an SSD and Benchmarking
- Part 3: Pages, Blocks, and the Flash Translation Layer
- Part 4: Advanced Functionalities and Internal Parallelism
- Part 5: Access Patterns and System Optimizations
- Part 6: A Summary – What every programmer should know about solid-state drives
References
-
Parameter-Aware I/O Management for Solid State Disks (SSDs), Kim et al., 2012 ↩ ↩2 ↩3
-
SFS: Random Write Considered Harmful in Solid State Drives, Min et al., 2012 ↩
-
Understanding Intrinsic Characteristics and System Implications of Flash Memory based Solid State Drives, Chen et al., 2009 ↩ ↩2 ↩3 ↩4
-
Design Tradeoffs for SSD Performance, Agrawal et al., 2008 ↩ ↩2
-
Essential roles of exploiting internal parallelism of flash memory based solid state drives in high-speed data processing, Chen et al, 2011 ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
http://www.storagereview.com/micron_p420m_enterprise_pcie_ssd_review ↩
-
http://www.acunu.com/2/post/2011/08/why-theory-fails-for-ssds.html ↩
-
http://blog.nuclex-games.com/2009/12/aligning-an-ssd-on-linux/ ↩
-
http://rethinkdb.com/blog/more-on-alignment-ext2-and-partitioning-on-ssds/ ↩
-
http://superuser.com/questions/228657/which-linux-filesystem-works-best-with-ssd/ ↩ ↩2
-
https://wiki.archlinux.org/index.php/Solid_State_Drives ↩ ↩2 ↩3
-
https://www.kernel.org/doc/Documentation/block/cfq-iosched.txt ↩
-
http://www.danielscottlawrence.com/blog/should_i_change_my_disk_scheduler_to_use_NOOP.html ↩
-
http://www.phoronix.com/scan.php?page=article&item=linux_iosched_2012 ↩
-
http://www.velobit.com/storage-performance-blog/bid/126135/Effects-Of-Linux-IO-Scheduler-On-SSD-Performance ↩